目录
基本概念
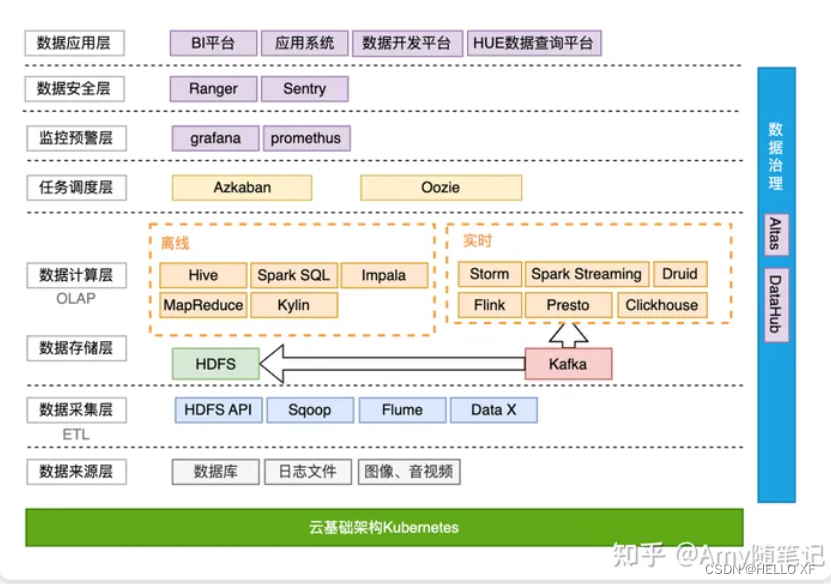
Hadoop生态
HIVE
hdfs(hadoop成员)
yarn(hadoop成员)
MapReduce(hadoop成员)
spark
flink
storm
HBase
kafka
ES
实战
安装并配置hadoop
环境准备
准备虚拟机
安装ssh并设置免密登录
安装jdk
安装、配置并启动hadoop
添加hadoop环境变量,不然启动会报错
Hadoop伪分布模式的搭建
配置免密登录
HDFS的配置
YARN的配置
启动Hadoop
启动hdfs
YARN集群启停
Hadoop集群启停(HDFS+YARN)
使用hadoop完成单词统计任务
hdfs存入文件
提交MapReduce任务
HIVE实战
基本概念
安装HIVE
#初始化元数据库
启动hive
尝试hive操作
hiveserver2实战
HIVE的表
Hive的复杂数据类型
ETL介绍
指标
#BI
磨刀不误砍柴工
Linux常用命令
#建文件夹
#关防火墙
#查看主机名
#删除
#查看启动服务
查看端口占用
hadoop命令
查看namenodes配置
基本概念
起初在谷歌研发,相关关键技术论文发表:
Google三篇论文
-
The' Google file systemy:谷歌分布式文件系统GFS
-
《MapReduce:Simplified Data Processing on Large Clusters》:谷歌分布式计算框架MapReduce
-
《Bigtable:A Distributed StorageSystemforStructured Data》:谷歌结构化数据存储系统
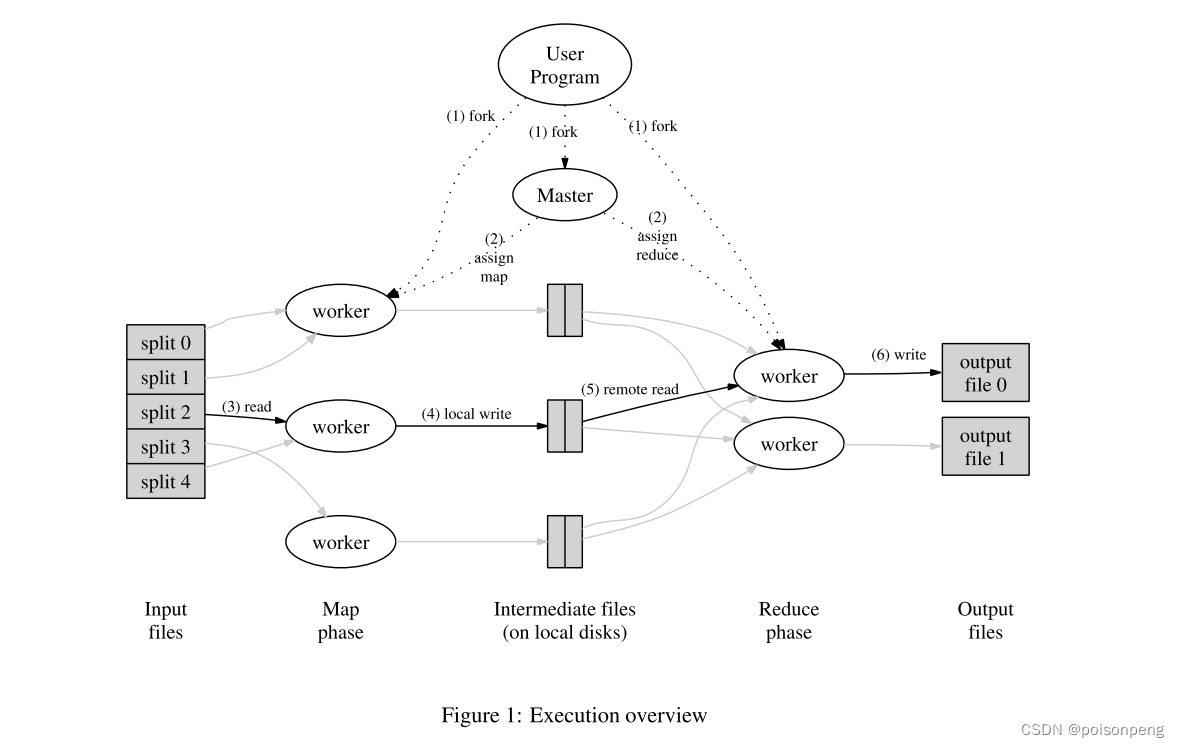
大数据开源项目hadoop的三驾马车,hdfs分布式存储,mapreduce分布式计算,yarn分布式调度

大数据的5V特征:
-
数据量大:一般以P(1000个TB)、E(100万个TB)或Z(10亿个TB)为计量单位
-
数据类型繁多:包括结构化、半结构化和非结构化的数据,数据来源多样,文本、日志、视频、图片、地理位置等;
-
价值密度低:大数据所具备的巨大体量,使其所包含信息较少。因此需要利用通过数据分析与机器学习更快速的挖掘出有价值的数据,带来更多的商业价值。
-
速度快:数据增长速度快、并要求处理速度快、对时效性要求也高,海量数据的处理需求不再局限在离线计算当中。
-
真实性:数据的真实性和可信赖度差异较大,因此数据分析的精确度也有所不同。
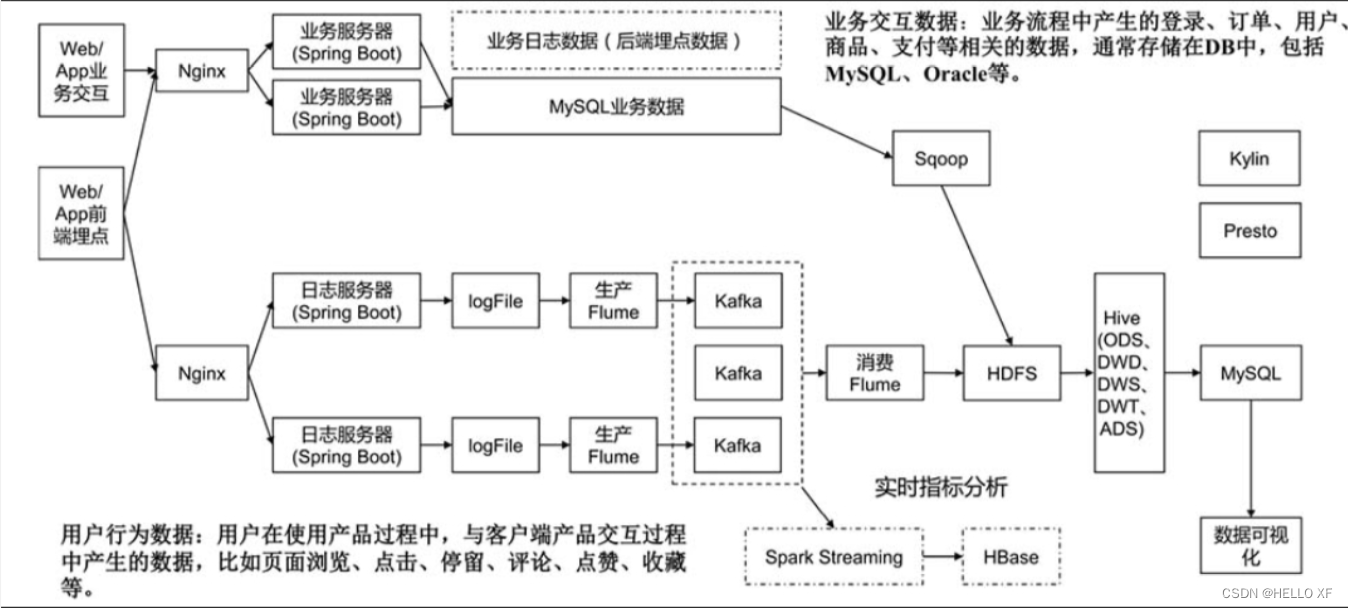
大数据平台本质上就是对海量数据从采集、存储、计算、应用、管理、运维的多方位、多维度的组合研究设计,从而建设合理、高效的大数据平台架构。HDFS是Hadoop提供的分布式存储框架,它可以用来存储海量数据,MapReduce是Hadoop提供的分布式计算框架,它可以用来统计和分析HDFS上的海量数据,而Hive则是SQL On Hadoop,Hive提供了SQL接口,开发人员只需要编写简单易上手的SQL语句,Hive负责把SQL翻译成MapReduce,提交运行。通过Hive命令行可以对数据进行创建表、删除表、往表中加载数据、分区、将表中数据下载到本地等操作。
Hadoop生态
HIVE
Hive是一个基于Hadoop的数据仓库工具,用于进行数据提取、转化、加载,以及存储、查询和分析大规模数据。Hive可以将结构化的数据文件映射为一张数据库表,并提供SQL查询功能,将SQL语句转变成MapReduce任务来执行。

Hive的主要功能和作用包括:
-
数据存储与管理:Hive能够将结构化数据存储在Hadoop分布式文件系统(HDFS)中,并提供表、分区、桶等抽象概念,方便管理和组织数据。
-
数据转换与集成:Hive支持ETL(抽取、转换、加载)操作,可以对原始数据进行清洗、转换和集成,以适应特定的分析需求。
-
查询与分析:通过HiveQL查询语言,用户可以使用类似于SQL的语法来执行复杂的查询操作,包括筛选、聚合、连接等,从而实现数据探索和分析。
-
扩展性与可扩展性:由于基于Hadoop生态系统构建,Hive具有良好的可扩展性,能够处理大规模的数据,并支持并行计算。
-
用户界面与工具支持:除了命令行接口外,Hive还提供了Web界面(如Hue)和其他第三方工具(如Apache Zeppelin),使用户能够更直观地进行交互和可视化分析。
Hive的特性包括面向主题性、集成性、非易失性和时变性。Hive的常见应用场景包括大数据分析、数据仓库、数据清洗和转换、数据集成、数据可视化和日志分析等。
总的来说,Hive是一个功能强大的数据仓库工具,可以帮助用户更好地管理和分析存储在Hadoop中的大规模数据。
hdfs(hadoop成员)
HDFS,即Hadoop Distributed File System,是一个被设计成适合运行在通用硬件上的分布式文件系统。它的主要目标是提供高吞吐量的数据访问,并适用于大规模数据集的应用。
在HDFS中,文件被切分成多个数据块,每个数据块默认大小为128MB。这些数据块会被分散存储在集群中的不同机器上,以实现数据的冗余备份和高可靠性。每个数据块都会有多个副本,这些副本分布在不同的机架上,以提高数据的容错性。
HDFS采用主从结构模型,由一个NameNode和若干个DataNode组成。NameNode作为主服务器,负责管理文件系统的命名空间和客户端对文件的访问操作。而DataNode则负责存储数据,每个数据块在DataNode上都有唯一的块ID。
在HDFS中,数据复制是提供容错性和高可用性的关键机制。默认情况下,每个数据块会有三个副本,其中一个副本存储在本地节点上,另外两个副本存储在不同的机架上的其他节点上。这样,即使某个节点或机架发生故障,数据仍然可以从其他副本中恢复。
此外,HDFS还通过检测数据块的副本是否损坏或丢失来提供容错恢复。如果某个数据块的副本损坏或丢失,HDFS会自动从其他副本中选择一个进行复制,以确保数据的完整性和可用性。
总之,HDFS是一个高度容错性的系统,适合部署在廉价的机器上,提供高吞吐量的数据访问,非常适合大规模数据集上的应用。它通过文件切分、数据复制和容错恢复等机制,实现了数据的冗余备份和高可靠性。

yarn(hadoop成员)
Hadoop YARN(Yet Another Resource Negotiator,另一种资源协调者)是Hadoop的一个分布式资源调度系统,它专门用于为分布式计算程序提供计算资源。YARN的基本原理是将计算框架的计算任务和资源需求分配给集群中可用的计算资源。
在YARN中,集群资源被抽象为一组可用的计算容器,每个容器都有一定的CPU、内存和其他资源。应用程序被划分为多个任务,每个任务对应一个或多个容器。任务由应用程序管理器(ApplicationMaster)负责维护和执行。资源管理器(ResourceManager)是YARN的核心组件,负责集群资源的全局调度和分配。它与节点管理器(NodeManager)通信,报告节点的状态和可用资源,并执行资源的分配和释放。
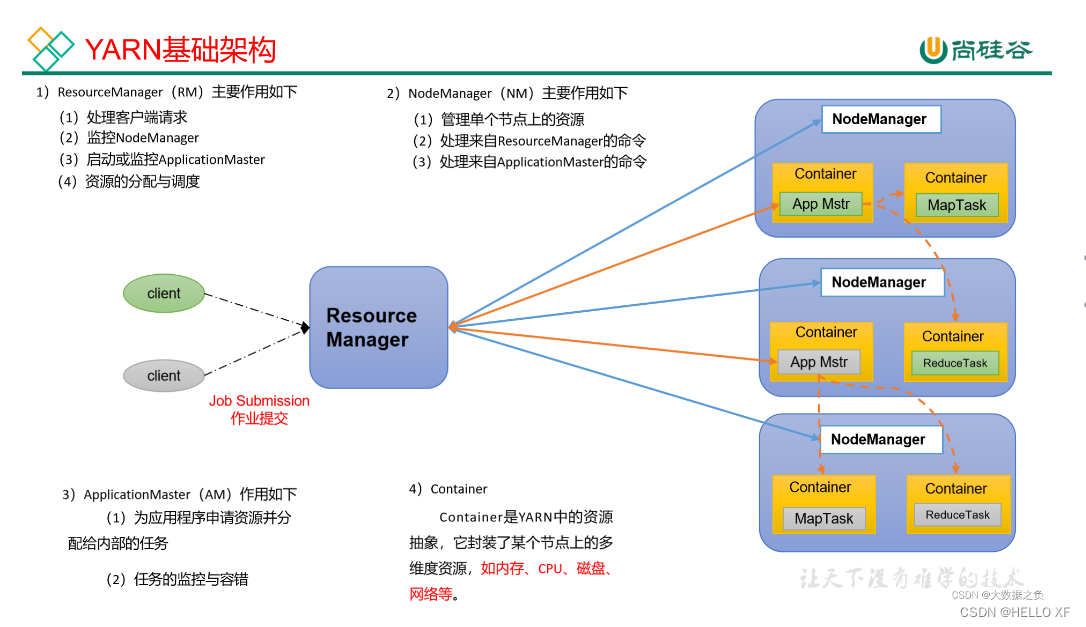
YARN的基本架构包括ResourceManager、ApplicationMaster和NodeManager。ResourceManager控制整个集群并管理应用程序向基础计算资源的分配。ApplicationMaster管理在YARN内运行的应用程序的每个实例,负责协调来自ResourceManager的资源,并通过NodeManager监视容器的执行和资源使用。NodeManager管理YARN集群中的每个节点,提供针对集群中每个节点的服务,从监督容器的终生管理到监视资源和跟踪节点健康。
YARN通过将计算资源从底层的集群中抽象出来,并提供一个统一的接口供应用程序进行资源管理和调度,实现了大规模数据处理任务的资源调度和执行。这种分布式计算框架能够实现高效的资源利用和任务执行,提高数据处理的性能和可伸缩性。同时,YARN还提供了容错机制和故障恢复功能,以确保任务的正常执行。
总之,Hadoop YARN是一个分布式资源调度系统,它通过抽象和管理集群资源,为上层应用提供统一的资源管理和调度。YARN的基本原理是将计算任务和资源需求分配给集群中可用的计算资源,通过ResourceManager、ApplicationMaster和NodeManager的协作,实现资源的全局调度和分配,以及任务的执行和监控。YARN的引入为集群在利用率、资源统一管理和数据共享等方面带来了巨大好处,使得分布式计算程序能够在YARN上进行高效的资源调度和执行。
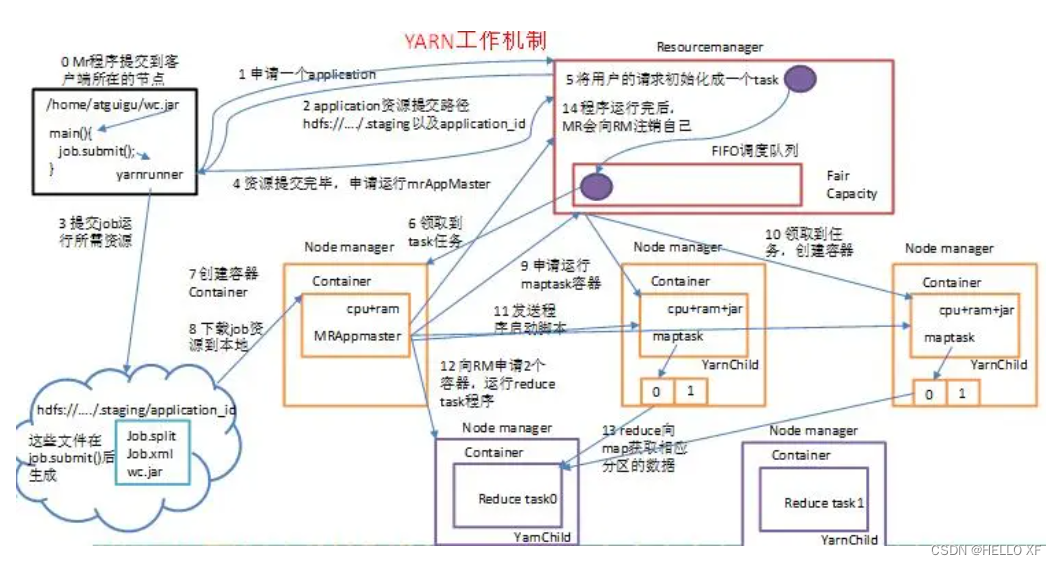
提交MapReduce程序至YARN运行
这些内置的示例MapReduce程序代码,都在:
$HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar 这个文件内。
可以通过 hadoop jar 命令来运行它,提交MapReduce程序到YARN中。
语法: hadoop jar 程序文件 java类名[程序参数]...[程序参数]

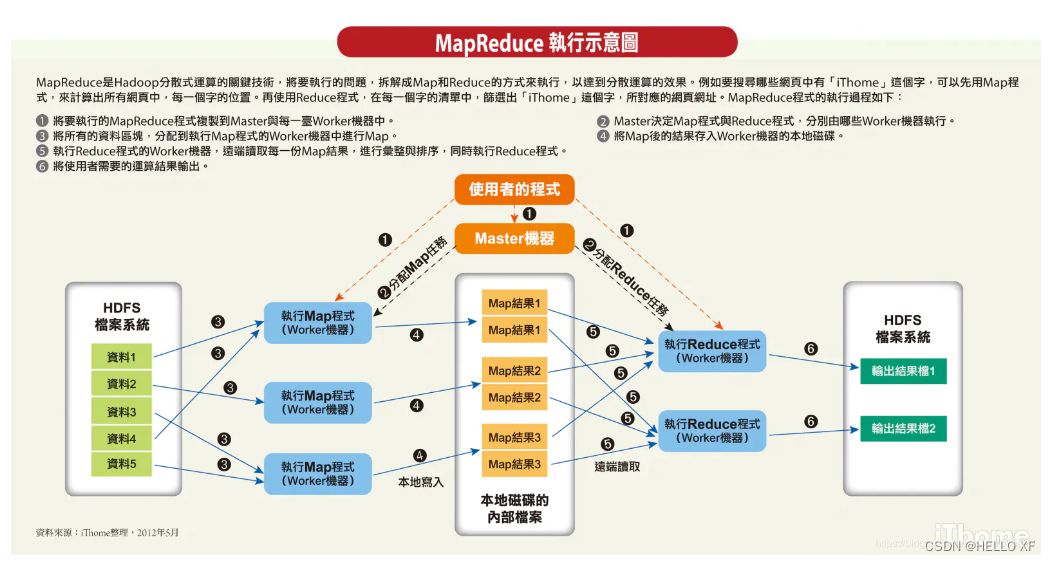
MapReduce(hadoop成员)
MapReduce是一种编程模型,用于处理大规模数据集(通常大于1TB)的并行运算。它主要包含两个核心概念:Map(映射)和Reduce(归约)。这两个概念都是从函数式编程语言里借来的,还有从矢量编程语言里借来的特性。MapReduce模型极大地方便了编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统上。
MapReduce的基本原理可以分为以下几个步骤:
-
**Map阶段**:在这个阶段,用户需要定义一个Map函数,该函数会处理输入数据集中的每一个元素,将其映射成一组新的键值对。例如,可以将一个文本文件的内容按照单词进行拆分,每个单词作为一个键,出现的次数作为值。
-
**Shuffle阶段**:在Map阶段完成后,系统会对所有的键值对进行排序,确保所有相同的键都在一起。这个过程称为Shuffle。
-
**Reduce阶段**:在这个阶段,用户需要定义一个Reduce函数,该函数会处理所有具有相同键的键值对,并生成最终的输出结果。例如,可以将所有相同的单词的出现次数进行累加,得到每个单词的总出现次数。
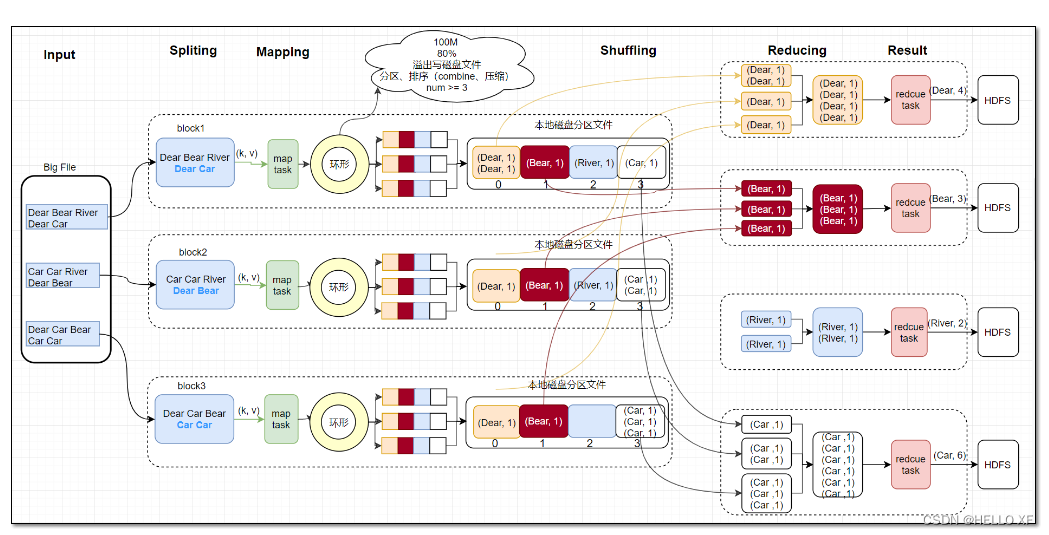
MapReduce模型允许用户在不了解分布式系统底层细节的情况下,利用大规模的计算资源处理海量的数据。它提供了一个庞大但设计精良的并行计算软件框架,能自动完成计算任务的并行化处理,自动划分计算数据和计算任务,在集群节点上自动分配和执行任务以及收集计算结果。这使得软件开发人员可以专注于业务逻辑的实现,而无需关心并行计算涉及到的数据分布存储、数据通信、容错处理等复杂细节。
MapReduce模型最早是由Google公司提出并应用于其搜索引擎中的大规模网页数据并行化处理。由于其普适性,现在已经被广泛应用于各种大规模数据处理问题中。
spark
Spark是一种快速、通用、可扩展的大数据分析引擎,它基于内存计算的大数据并行计算框架,包含了SparkSQL、Spark Streaming、GraphX、MLlib等子项目。Spark不仅支持Scala编写应用程序,还支持Java和Python等语言进行编写,特别是Scala是一种高效、可拓展的语言,能够用简洁的代码处理较为复杂的处理工作。Spark的通用性强,其生态圈即BDAS(伯克利数据分析栈)包含了多个组件,这些组件能够无缝集成并提供一站式解决平台。此外,Spark的容错性也很高。
Spark已经被广泛应用于各个行业,包括金融、电商、医疗、制造业等。例如,在金融行业,Spark被用于风险评估、诈骗检测、客户分析等;在电商行业,Spark被用于商品推荐、用户行为分析、库存管理等;在医疗行业,Spark被用于病例分析、药物研发、医疗数据管理等;在制造业,Spark被用于生产数据分析、质量控制、供应链管理等。
总的来说,Spark是一种功能强大、易于使用、通用性强的大数据分析引擎,已经成为越来越多技术团队和企业的首选工具。
flink
Flink是一个开源的流处理框架,专为分布式、高性能、随时可用和准确的流处理应用程序打造。它不仅可以处理无界和有界数据流,还具备有状态计算的能力。这意味着程序可以保持已经处理过的数据状态,从而确保在数据源无序或晚到达时,仍能保持结果的准确性。
Flink的特性包括:
-
精确一次的状态一致性:Flink支持仅一次语义状态计算,确保在发生故障时能够无缝恢复,并保持数据的精确性,实现零数据丢失。
-
高吞吐量和低延迟:Flink的设计使得它能够在所有常见的集群环境中运行,以内存执行速度和任意规模来执行计算,从而实现高吞吐量和低延迟。
-
容错性:Flink的容错机制是轻量级的,能够在同一时间维持高吞吐率和提供仅一次的一致性保证。
-
版本控制:Flink的保存点提供版本控制机制,使得应用程序的更新或历史数据的再加工不会丢失,且在最小的停机时间内完成。
此外,Flink还具有广泛的应用场景,包括机器学习、事件驱动应用、复杂事件处理以及实时报表和可视化等。通过Flink的流处理能力,可以实现对实时数据的特征提取和模型训练,提高机器学习的效率和准确性。同时,Flink也可以用于构建事件驱动的应用,如物联网、智能交通、金融风控等,实现对事件的实时捕获、处理和响应。在复杂事件处理方面,Flink可以高效处理和分析事件聚合、事件关联、事件过滤等场景,提高业务决策的准确性和效率。最后,Flink还可以用于实时报表和可视化任务,如实时监控大屏、实时报表生成等,实现对数据的实时分析和可视化,提高业务决策的及时性和可视化效果。
storm
Storm是一个用于处理和分析实时数据流的开源分布式计算系统。它具有低延迟、高性能、可扩展和高可靠性等特点,可以用于处理各种实时数据流,如社交媒体数据、日志文件、网络流量数据等。
Storm主要由工作进程、线程和任务三个实体组成,可以在集群中并行处理数据流。每个工作进程可以创建多个线程,每个线程可以执行多个任务,从而实现高效的数据处理。
Storm支持多种编程语言,如Java、Clojure和Python等,使得开发人员可以使用自己熟悉的编程语言来编写Storm任务。
除了实时分析外,Storm还可以用于事件处理、数据转换和清洗、机器学习、分布式RPC和连续计算等多种场景。它可以通过流式计算模型对实时数据流进行实时分析和处理,为各种应用场景提供实时决策支持和预测分析。
总的来说,Storm是一个强大而灵活的实时数据处理系统,可以应对各种复杂的实时数据处理场景。
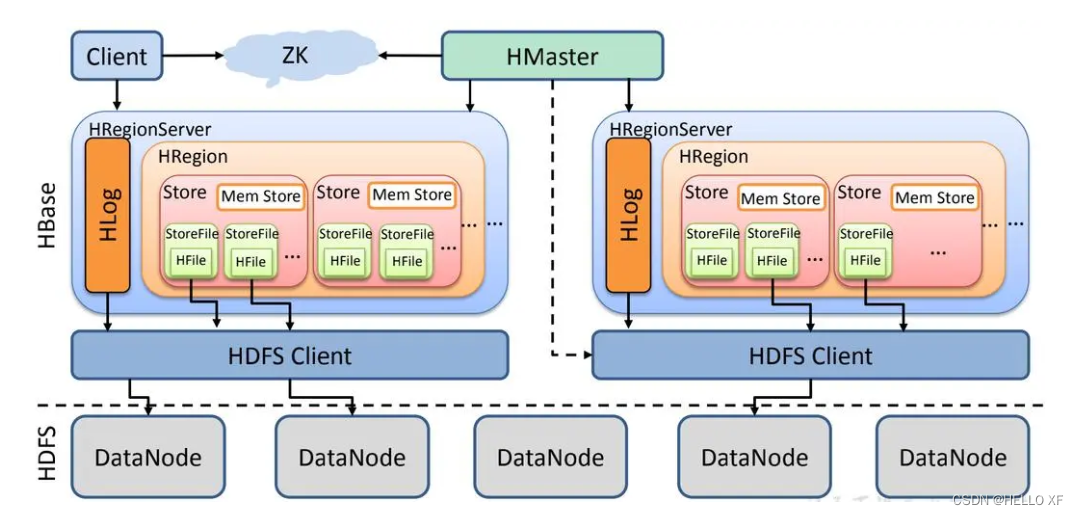
HBase
HBase是一个分布式的、面向列的开源数据库,它源于Fay Chang在Google所撰写的论文“Bigtable:一个结构化数据的分布式存储系统”。HBase在Hadoop之上提供了类似于Bigtable的能力,并作为Apache的Hadoop项目的子项目存在。
HBase有以下主要特点:
-
表大:一个表可以拥有数亿行和上百万列。
-
无模式:每行都有一个可排序的主键和任意多的列,列可以根据需要动态增加,同一个表中的不同行可以有截然不同的列。
-
面向列存储和权限控制:列族拥有独立索引。
-
数据稀疏:空(null)列不占用空间,表可以设计得非常稀疏。
-
数据类型单一:HBase中的数据都是字符串,没有类型。
HBase的架构是基于Master/Slave的,并且它隶属于Hadoop生态系统。它由以下类型的节点组成:HMaster节点、HRegionServer节点和ZooKeeper集群。在底层,HBase将数据存储于HDFS中,因此还涉及到HDFS的NameNode和DataNode。
HBase的主要应用场景包括:
-
大规模数据存储和管理:适用于存储和管理大规模数据集,如互联网应用中的用户数据、日志数据等。
-
实时数据分析和处理:支持实时数据读写操作,适用于需要实时分析和处理数据的场景,如实时监控系统、实时推荐系统等。
-
多维数据分析:支持多维数据分析,适用于数据分析和挖掘等场景。
-
分布式系统的元数据存储:可以作为分布式系统的元数据存储,用于存储系统配置信息、状态信息等。
-
分布式日志存储:适用于存储分布式系统的日志数据,如分布式文件系统日志、数据库事务日志等。
总的来说,HBase是一个适合非结构化数据存储的数据库,特别适用于需要处理大规模、稀疏和动态扩展的数据的场景。
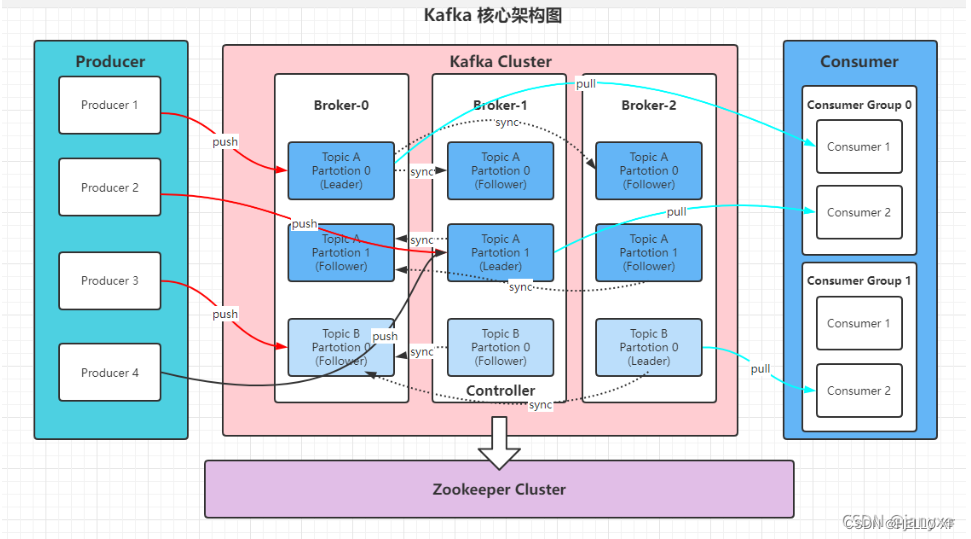
kafka
Kafka是由Apache软件基金会开发的一个开源流处理平台,用Scala和Java编写。它是一个高吞吐量的分布式发布订阅消息系统,能够处理消费者在网站中的所有动作流数据,如网页浏览、搜索和其他用户行动。这些数据在现代网络上对社会功能至关重要,并通常通过处理日志和日志聚合来满足吞吐量的要求。
Kafka的特性和优势包括:
-
高吞吐量、低延迟:Kafka每秒可以处理几十万条消息,延迟最低只有几毫秒。
-
可扩展性:Kafka集群支持热扩展。
-
持久性、可靠性:消息被持久化到本地磁盘,并且支持数据备份以防止数据丢失。
-
容错性:允许集群中节点失败(若副本数量为n,则允许n-1个节点失败)。
-
高并发:支持数千个客户端同时读写。
Kafka在多种场景下都有广泛应用,如:
-
消息队列:Kafka是一个很好的消息系统替代方案,具有强大的扩展性和性能优势。
-
网站活动追踪:Kafka可以作为“网站活性跟踪”的最佳工具,将网页/用户操作等信息发送到Kafka中,并进行实时监控或离线统计分析。
-
指标:Kafka常用于监测数据,收集分布式应用程序生成的统计数据。
-
日志聚合:许多人使用Kafka作为日志聚合解决方案的替代品,处理基于单个主题的实时数据流。
-
事件采集:Kafka支持事件采集,这是一种应用程序设计风格,其中状态的变化根据时间的顺序记录下来。
在Kafka的架构中,主要组件包括:
-
Broker:Kafka集群中的服务器节点,主要负责管理Topic的Partition。
-
消费者:Topic中运行的应用程序,负责从该Topic读取消息,并能在指定的Partition上消费并处理这些消息。
-
Offset:用于标识每个Partition中的消息,它是一个唯一的值,用于表示消息在Partition中的位置。
-
Partition:Topic的子集,每个Partition相当于一个有序的消息系列,具备独立扩展和复制的能力,从而增强并发和容错性。
-
Producer:Kafka中的关键组件,主要负责将数据发送到目标Topic的应用程序。
-
Topic:Kafka数据流中的类别或主题,用于发送数据到或从主题中读取数据。
至于Kafka的部署方式,有以下几种选择:
-
单节点部署:在单台服务器上运行Kafka,适用于小规模数据处理和测试环境。
-
多节点部署:在多台服务器上运行Kafka,可以提高系统的容错性和性能,适用于生产环境。
-
容器化部署:使用容器技术(如Docker)将Kafka部署在容器中,方便部署和管理。
-
云端部署:将Kafka部署在云平台上,可以根据需求快速扩展和管理集群。
-
Kubernetes部署:使用Kubernetes进行Kafka集群管理,实现自动化部署、伸缩和监控。
以上信息仅供参考,如需了解更多关于Kafka的信息,建议咨询专业技术人员或者访问Apache Kafka的官方网站。
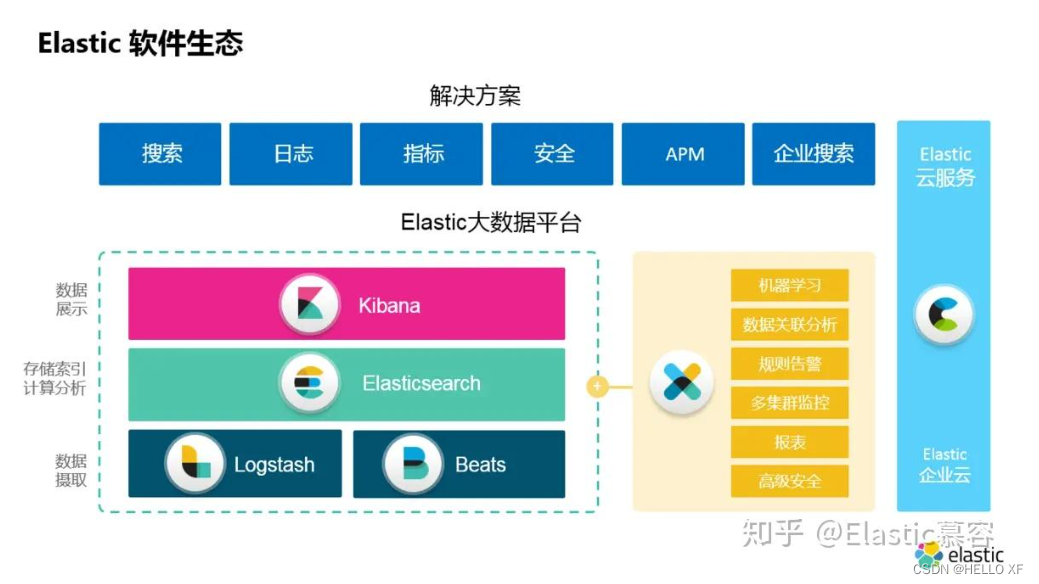
ES
Elasticsearch是一个基于Lucene的开源、分布式、RESTful搜索引擎。它设计用于云计算中,能够达到实时搜索、稳定、可靠、快速、安装使用方便等特性。
Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于全文搜索、结构化搜索、分析,以及这三个领域的所有组合。它的分布式特性意味着数据可以在多台机器上被索引和搜索;同时扩展性良好,能够随着数据量的增长而增长。
Elasticsearch提供一套简单一致的RESTful API,这使得Elasticsearch易于使用和集成。它允许用户以JSON格式发送请求和接收响应,这意味着任何可以使用HTTP请求的应用都可以与Elasticsearch进行通信。这使得Elasticsearch可以与各种语言和框架进行集成。
此外,Elasticsearch还提供了丰富的插件生态系统,允许用户扩展其功能以满足特定的需求。这些插件可以用于增强搜索、安全性、监控、数据导入导出等方面。
总的来说,Elasticsearch是一个强大而灵活的搜索引擎,广泛应用于各种需要实时搜索和分析的场景,如日志分析、全文搜索、安全智能、推荐系统等。
实战
安装并配置hadoop
环境准备
Hadoop的模式主要可以分为以下几种:
-
独立模式(本地模式):这是Hadoop的默认模式,无需运行任何守护进程,所有程序都在单个JVM上执行。这种模式主要用于对MapReduce程序的逻辑进行调试,确保程序的正确性。
-
伪分布式模式:这种模式在单机上运行,使用分布式文件系统,但在单机上启动NameNode、DataNode、secondary NameNode等。这种模式模拟了集群环境,但只有一个节点,因此副本为1。
-
完全分布式模式:在这种模式下,Hadoop在多台机器上运行,NameNode、DataNode、secondary NameNode等在不同的机器上启动。这种模式有多个节点,副本不唯一。
-
HA(High Availability)模式:这是完全分布式模式的一种改进,主要体现在高可用方式上。在这种模式下,有多台NameNode,其中只有一台是对外提供服务的(主),其他的机器只有在主NameNode挂掉后才会承接起对外服务的功能。这种方式提高了Hadoop集群的可用性和稳定性。
以上四种模式是Hadoop中常见的运行模式,根据具体的需求和场景,可以选择适合的模式进行部署和使用。
准备虚拟机
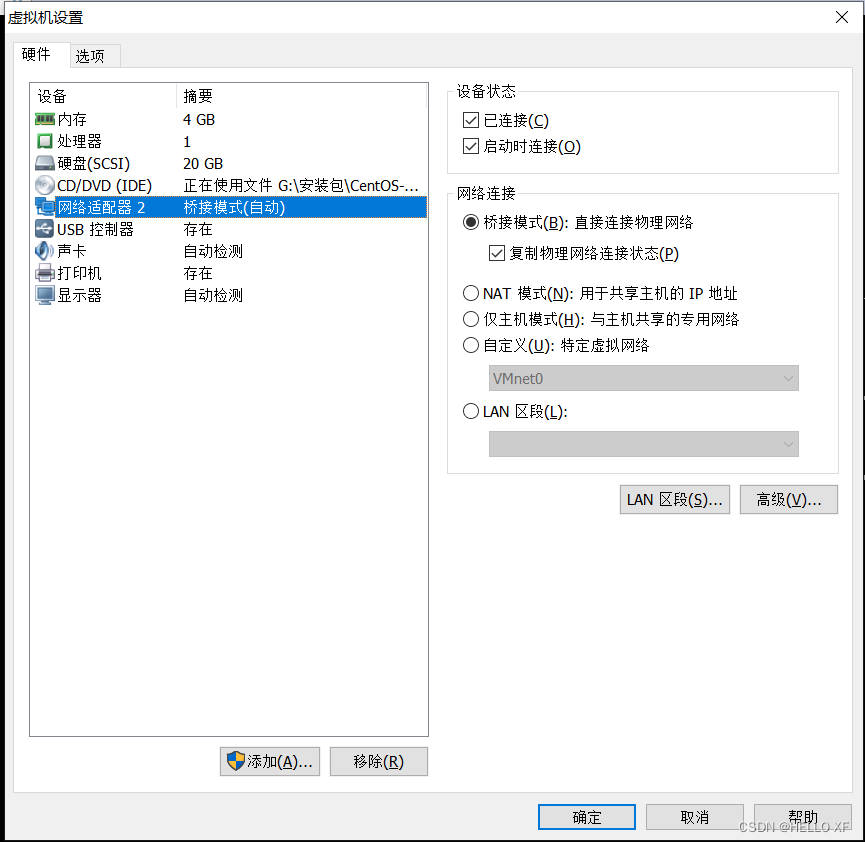
安装ssh并设置免密登录
sudo yum install -y openssh-server
在本地机器上生成SSH密钥对(如果你还没有的话):
ssh-keygen -t rsa
按照提示操作,你可以选择使用密码保护密钥,也可以直接留空。
将你的公钥复制到CentOS服务器上的~/.ssh/authorized_keys文件中:
cat id_rsa.pub >> authorized_keys
尝试免密能否登录
ssh localhost
安装jdk
因为hadoop是java语言编写的,所以安装运行hadoop之前需要在服务器安装jdk并配置java环境变量
sudo mkdir /usr/lib/jvm
#解压
sudo tar -zxvf jdk-8u171-linux-x64.tar.gz -C /usr/lib/jvm
#配置环境变量
vi ~/.bashrc
# 在文件的开头位置,添加如下几行内容,这里jdk目录名为 jdk1.8.0_171
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_171
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
执行命令使环境变量生效
source ~/.bashrc
#验证java
java -version
安装、配置并启动hadoop
安装包目录说明
bin hadoop最基本的管理脚本和使用脚本的目录,这些脚本是sbin目录下管理脚本的基础实现,用户可以直接使用这些脚本管理和使用hadoop
etc hadoop配置文件所在的目录
include 对外提供的编程库头文件(具体动态库和静态库在lib目录中),这些文件均是用c++定义,通常用于c++程序访问HDFS或者编写MapReduce程序。
lib 该目录包含了hadoop对外提供的编程动态库和静态库,与include目录中的头文件结合使用。
libexec 各个服务队用的shell配置文件所在的免疫力,可用于配置日志输出,启动参数(比如JVM参数)等基本信息。
sbin hadoop管理脚本所在的目录,主要包含HDFS和YARN中各类服务的启动、关闭脚本。
share hadoop 各个模块编译后的jar包所在的目录。官方示例也在其中
# 解压Hadoop压缩文件到usr/local
sudo tar -zxvf hadoop-3.2.2.tar.gz -C /usr/local
# 给hadoop-3.2.2文件改名为hadoop
sudo mv hadoop-3.2.2 hadoop
# 修改文件权限
sudo chown -R hadoop ./hadoop
cd hadoop
# 查看hadoop版本,验证是否安装成功
bin/hadoop version
配置环境变量
vi ~/.bashrc
export HADOOP_HOME=/usr/local/hadoop/
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
classpath相关环境变量配置
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HADOOP_CLASSPATH=.:$HADOOP_HOME/bin/hadoop classpath
# 加载
$ source ~/.bashrc
添加hadoop环境变量,不然启动会报错
这个错误提示表明你正在尝试以 root 用户身份操作 HDFS 的 Namenode,但是没有定义 HDFS_NAMENODE_USER 环境变量
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_JOURNALNODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
Hadoop伪分布模式的搭建
配置免密登录
1. 本机生成公钥、私钥和验证文件,输入以下命令之后一直回车即可
| ssh-keygen -t rsa |
|---|
2. 将登录信息复制到验证文件,master为主机名
| ssh-copy-id master |
|---|
HDFS的配置
0. 进入Hadoop主目录
| cd /opt/hadoop-3.3.6 |
|---|
1. 配置hadoop-env.sh
| vi etc/hadoop/hadoop-env.sh |
|---|
在文件第25行去掉注释符,添加java路径:
| export JAVA_HOME=/usr/java/default |
|---|
2. 配置core-site.xml
| vi etc/hadoop/core-site.xml |
|---|
配置如下:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoopTmp/tmp</value>
</property>
</configuration>
3. 配置hdfs-site.xml
vi etc/hadoop/hdfs-site.xml
配置如下:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
4. 格式化HDFS
| hdfs namenode -format |
|---|
看到“Storage directory /opt/hadoopTmp/tmp/dfs/name has been successfully formatted.”,即格式化成功。
注意:以后修改配置文件重新格式化时,都要先删除tmp文件和logs文件
| rm -rf /opt/hadoopTmp/ |
| rm -rf /opt/hadoop-3.3.6/logs/ |
5. 正常来说,会生成current目录
YARN的配置
0. 进入Hadoop主目录
| cd /opt/hadoop-3.3.6 |
|---|
1. 配置yarn-site.xml
| vi etc/hadoop/yarn-site.xml |
|---|
配置如下:
<configuration>
<property>
<name>yarn.resourcemanager.hostsname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
日志聚合配置(可以在webui查看任务执行logs):
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>640800</value>
</property>
2. 配置mapred-site.xml
| vi etc/hadoop/mapred-site.xml |
|---|
配置如下:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
启动Hadoop
1. 使用如下命令,同时启动或停止HDFS和YARN
| start-all.sh |
| stop-all.sh |
2.使用如下命令查看结果
| jps |
|---|
当NameNode、SecondaryNameNode、DataNode、Jps、ResourceManager、NodeManager全部显示出来时,说明伪分布式安装成功

3. 访问Web端
(1)注意每次访问之前记得关闭防火墙
| systemctl stop firewalld.service |
|---|
(2)访问HDFS,Hadoop2的端口号是50070,Hadoop3的端口号是9870
http://192.168.10.8:9870

访问YARN
http://192.168.10.8:8088

启动hdfs
$ start-dfs.sh
$ stop-dfs.sh #这里不执行
http://192.168.10.8:9870
YARN集群启停
$ start-yarn.sh
$ stop-yarn.sh # 这里不执行# 查看java进程
$ jps
http://192.168.10.8:8088
Hadoop集群启停(HDFS+YARN)
$ start-all.sh
$ stop-all.sh
关防火墙 不然访问不了
systemctl stop firewalld.service
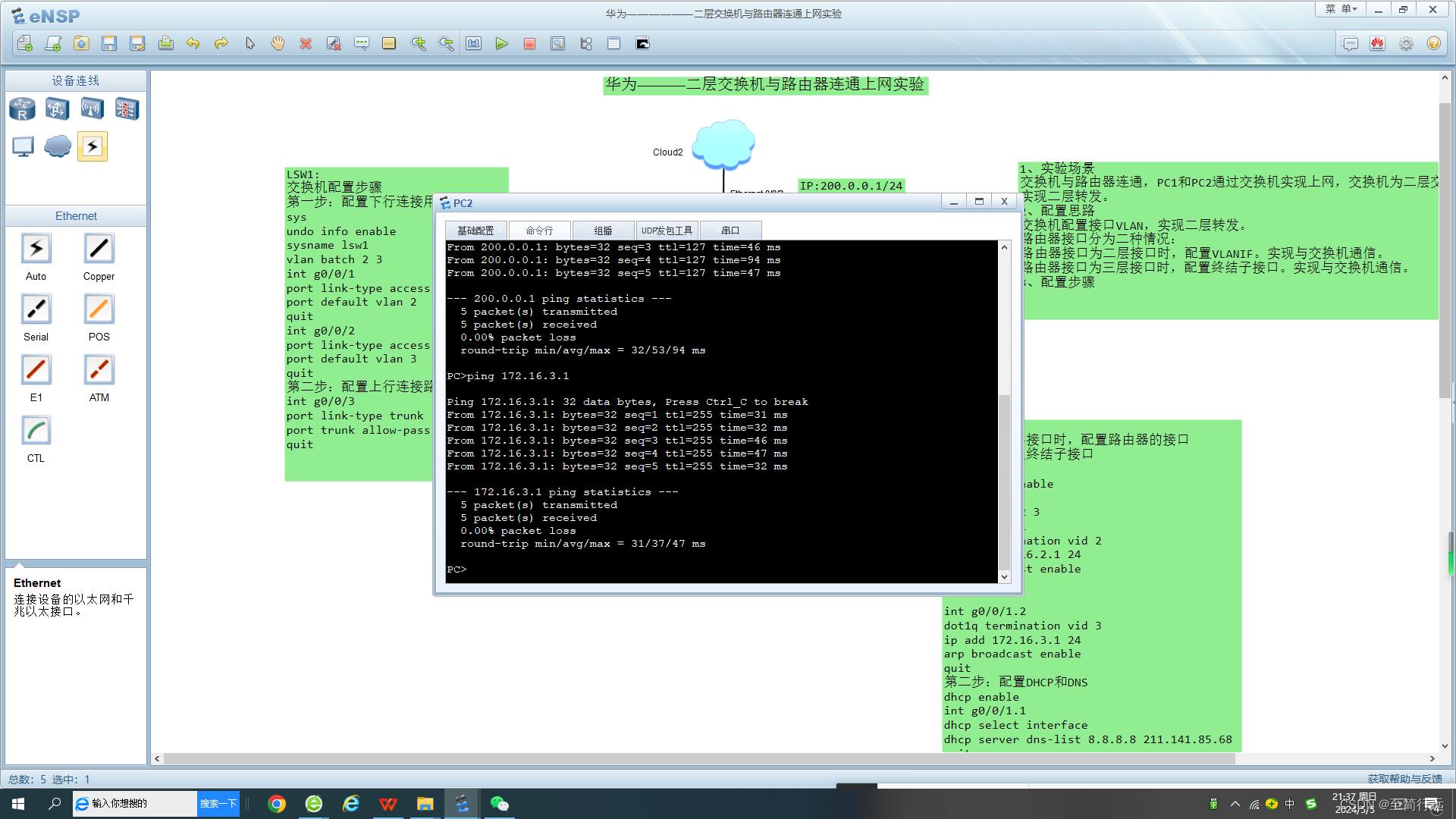
使用hadoop完成单词统计任务
hdfs存入文件
#创建需要统计单词计数的测试文件
vi words.txt
输入任意词语
esc + :wq 保存退出
#hdfs中创建准备用于存放输入输出的文件夹
[root@helloxf-pc hadoop]# hadoop fs -mkdir -p /input
[root@helloxf-pc hadoop]# hadoop fs -mkdir -p /output
#查看创建的文件夹
[root@helloxf-pc hadoop]# hadoop fs -ls /
Found 3 items
drwxr-xr-x - root supergroup 0 2024-05-05 10:22 /data
drwxr-xr-x - root supergroup 0 2024-05-05 10:22 /input
drwxr-xr-x - root supergroup 0 2024-05-05 10:23 /output
#将文件存入hdfs
hadoop fs -put words.txt /input/
#查看结果
hadoop fs -ls /input
提交MapReduce任务
hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.2.jar wordcount hdfs://master:9000/input hdfs://master:9000/output/wc
查看yarn地址发现多了任务
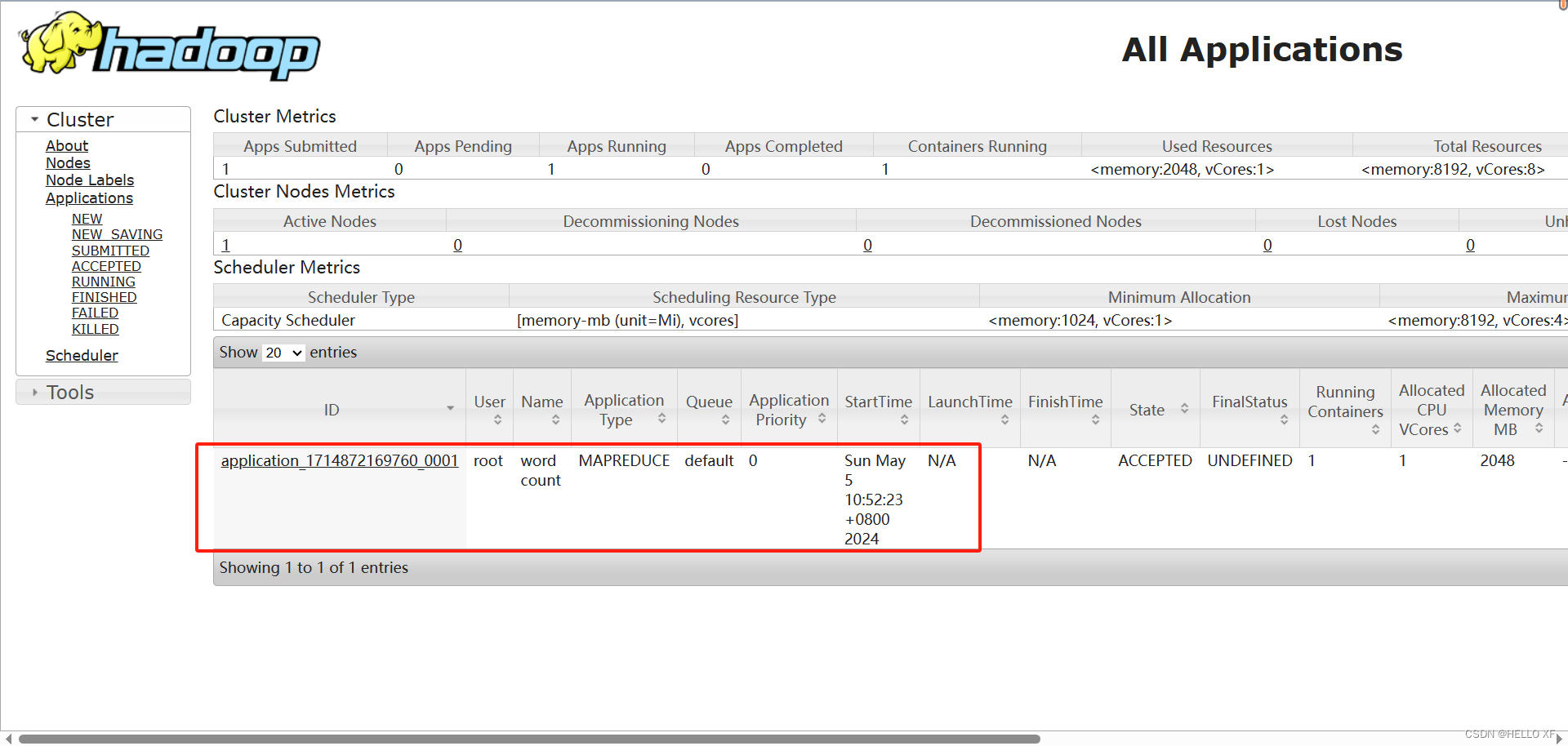
发现报错了:Error: Could not find or load main class org.apache.hadoop.mapreduce.v2.app.MRAppMaster
解决方法:
#查看hadoop的classpath
hadoop classpath
修改yarn-site.xml文件
找到yarn-site.xml和mapred-site.xml,并在configuration标签中,添加如下代码(value替换成自己的hadoop classpath路径):
<property>
<name>yarn.application.classpath</name>
<value>/usr/local/hadoop/etc/hadoop:/usr/local/hadoop/share/hadoop/common/lib/*:/usr/local/hadoop/share/hadoop/common/*:/usr/local/hadoop/share/hadoop/hdfs:/usr/local/hadoop/share/hadoop/hdfs/lib/*:/usr/local/hadoop/share/hadoop/hdfs/*:/usr/local/hadoop/share/hadoop/mapreduce/lib/*:/usr/local/hadoop/share/hadoop/mapreduce/*:/usr/local/hadoop/share/hadoop/yarn:/usr/local/hadoop/share/hadoop/yarn/lib/*:/usr/local/hadoop/share/hadoop/yarn/*:.:/usr/local/hadoop/bin/hadoop</value>
</property>
再次执行:
hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.2.jar wordcount hdfs://master:9000/input hdfs://master:9000/output/wc
日志如下:
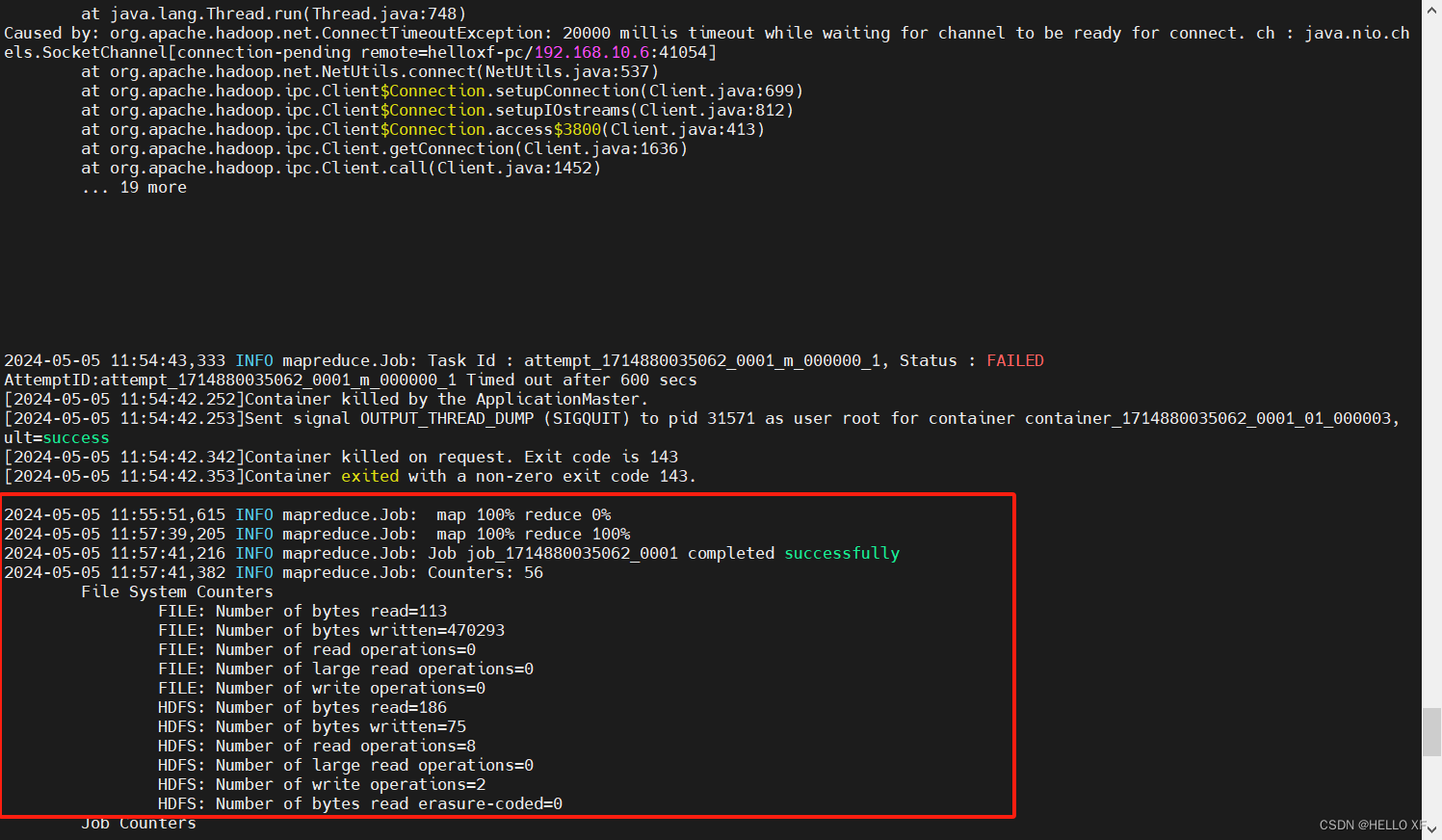
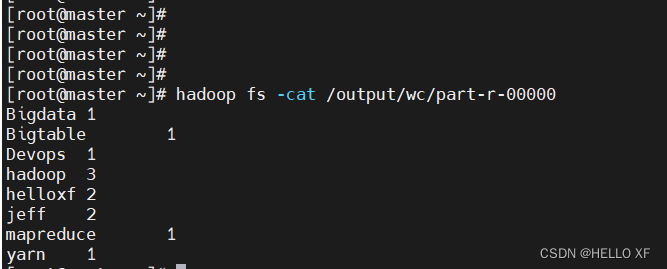
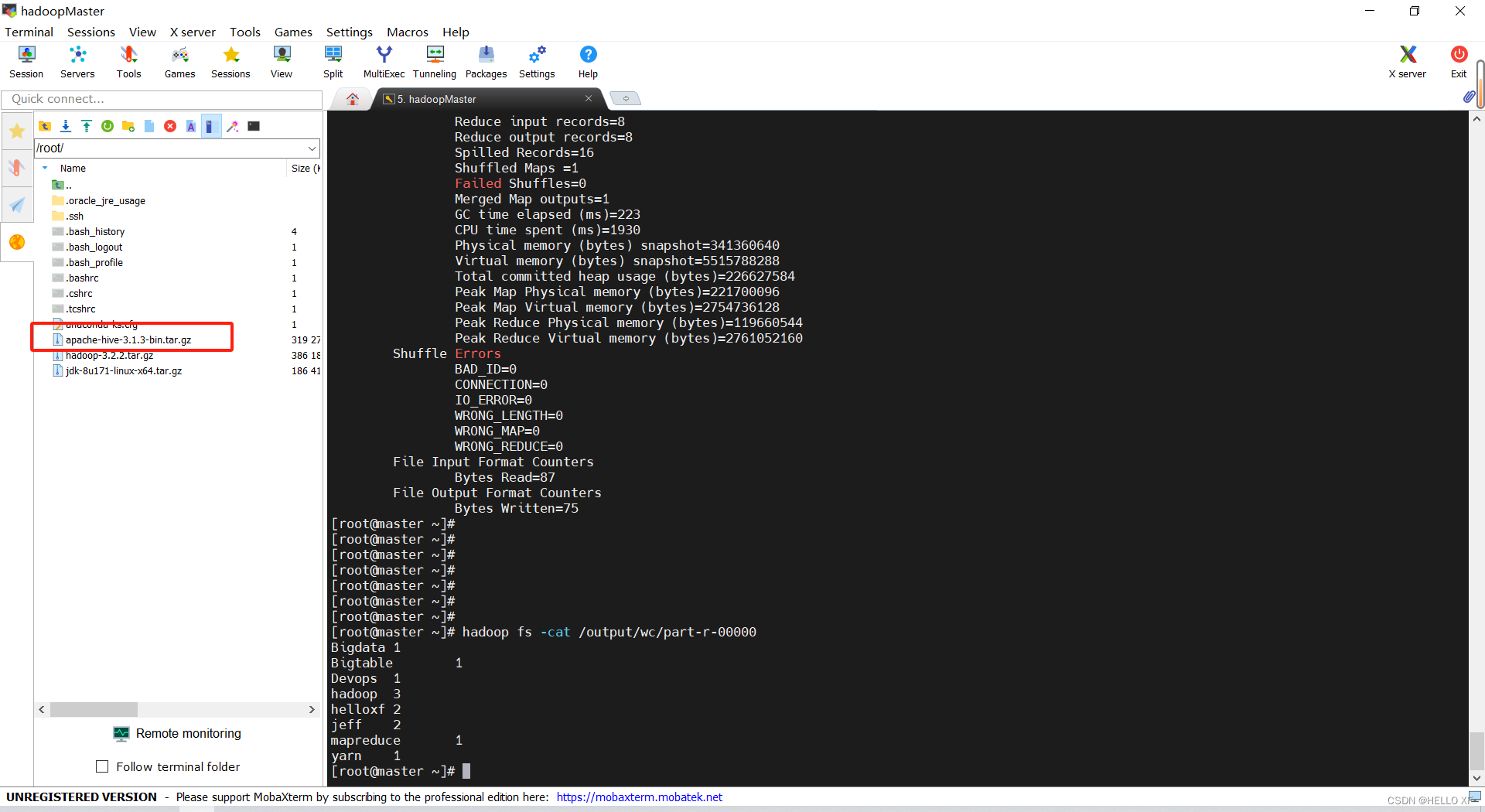
#查看结果
hadoop fs -cat /output/wc/part-r-00000
HIVE实战
基本概念
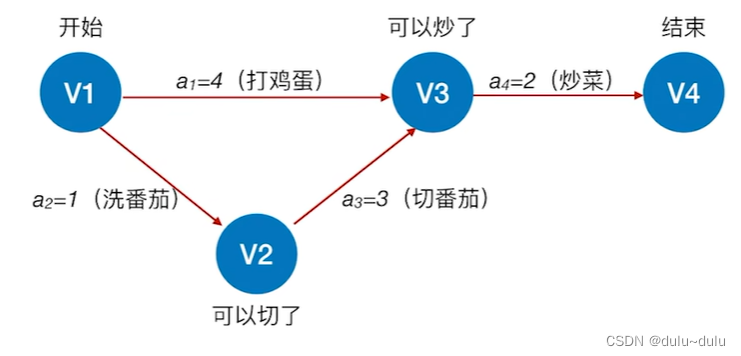
Apache Hive其2大主要组件就是:SQL解析器以及元数据存储,如下图。
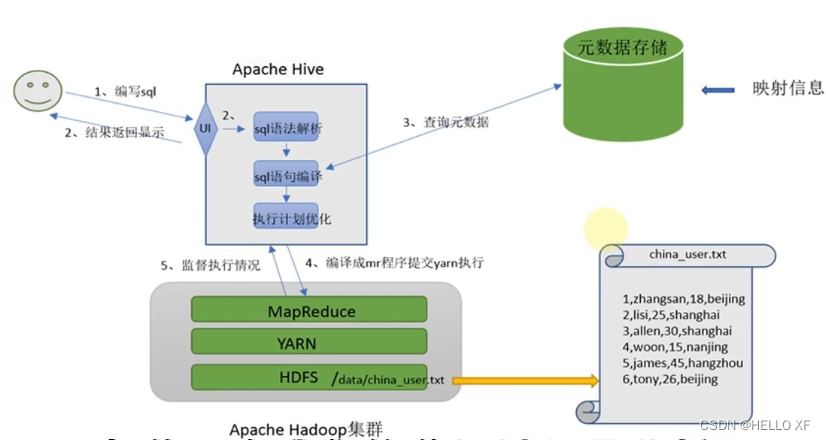
架构图

安装HIVE
下载拷贝安装包到服务器
修改 hadoop 集群的 core-site.xml 配置文件
加入两条配置信息:表示设置 hadoop 的代理用户
配置解析:
hadoop.proxyuser.hadoop.hosts 配置成*的意义,表示任意节点使用 hadoop 集群的代理用户 hadoop 都能访问 hdfs 集群,hadoop.proxyuser.hadoop.groups 表示代理用户的组所属
以上操作做好了之后(最好重启一下HDFS集群)
<property>
<name>hadoop.proxyuser.hadoop.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.groups</name>
<value>*</value>
</property>
#解压hive
mkdir /export
mkdir /export/server/
tar -zxvf apache-hive-3.1.3-bin.tar.gz -C /export/server/
#设置软连接
ln -s /export/server/apache-hive-3.1.3-bin /export/server/hive
#移入mysql驱动包
mv mysql-connector-java-5.1.42.jar /export/server/hive/lib/
#修改hive配置
在Hive的conf目录内,新建hive-env.sh文件,填入以下环境变量内容
export HADOOP_HOME=/usr/local/hadoop/
export HIVE_CONF_DIR=/export/server/hive/conf
export HIVE_AUX_JARS_PATH=/export/server/hive/lib
#进入hive的conf目录,修改以下文件名
mv hive-env.sh.template hive-env.sh
#准备hive-site.xml配置文件
vi hive-site.xml
<configuration>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<!--hive 元数据库的JDBC驱动类,这里选则 MySQL-->
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
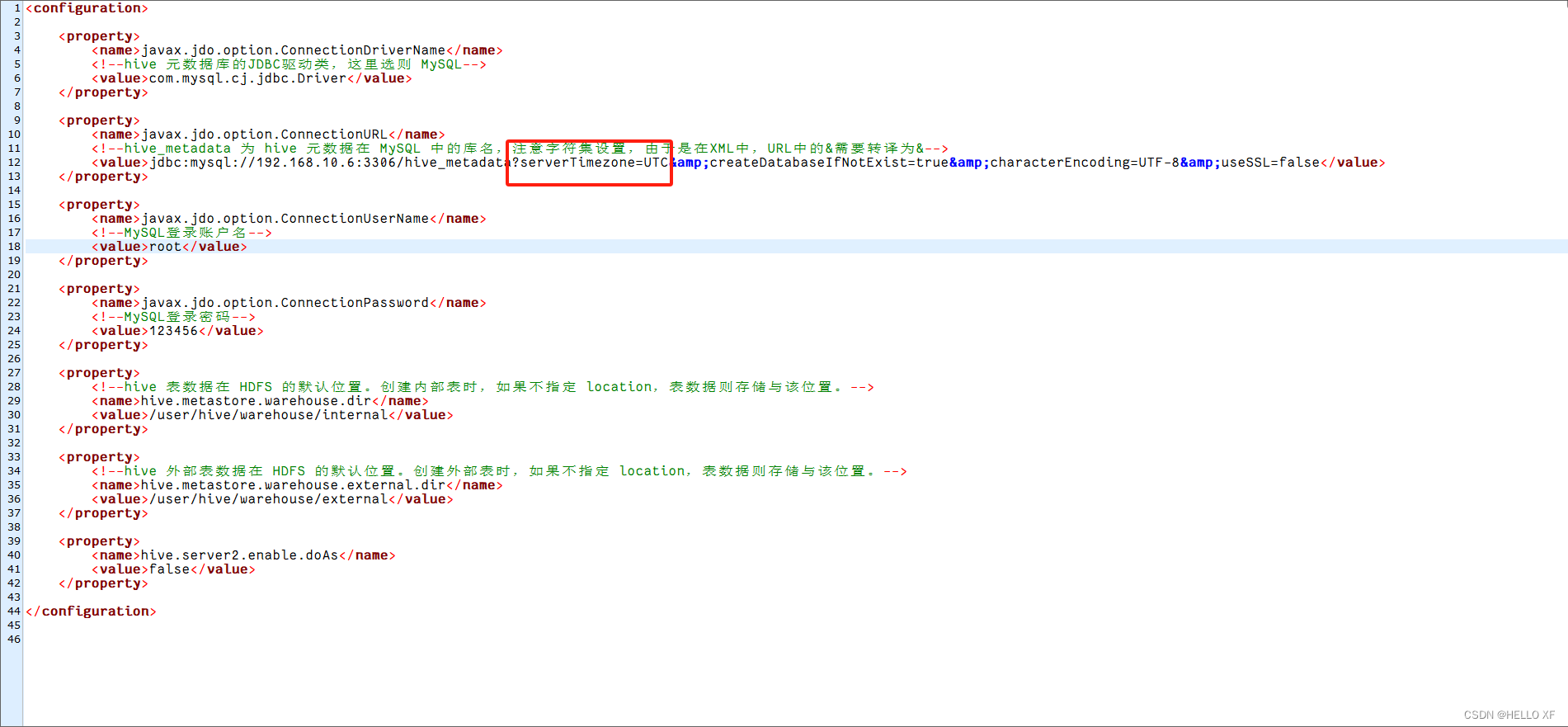
<!--hive_metadata 为 hive 元数据在 MySQL 中的库名,注意字符集设置,由于是在XML中,URL中的&需要转译为&-->
<value>jdbc:mysql://192.168.10.6:3306/hive_metadata?createDatabaseIfNotExist=true&characterEncoding=UTF-8&useSSL=false</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<!--MySQL登录账户名-->
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<!--MySQL登录密码-->
<value>123456</value>
</property>
<property>
<!--hive 表数据在 HDFS 的默认位置。创建内部表时,如果不指定 location,表数据则存储与该位置。-->
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse/internal</value>
</property>
<property>
<!--hive 外部表数据在 HDFS 的默认位置。创建外部表时,如果不指定 location,表数据则存储与该位置。-->
<name>hive.metastore.warehouse.external.dir</name>
<value>/user/hive/warehouse/external</value>
</property>
<property>
<name>hive.server2.enable.doAs</name>
<value>false</value>
</property>
</configuration>
#初始化元数据库
./schematool -initSchema -dbType mysql -verbos
#报错了
[root@master bin]# ./schematool -initSchema -dbType mysql -verbos
Exception in thread "main" java.lang.NoSuchMethodError: com.google.common.base.Preconditions.checkArgument(ZLjava/lang/String;Ljava/lang/Object;)V
#原因是hive中guava包版本比hadoop低,解决办法是复制hadoop中的包到hive中:
mv "/export/server/apache-hive-3.1.3-bin/lib/guava-19.0.jar" /root/guava-19.0.jar
还有有报错:
Underlying cause: java.sql.SQLException : Unknown system variable 'query_cache_size'
原因是mysql包版本太低,要替换成8.+
mv /root/mysql-connector-java-8.0.16.jar /export/server/hive/lib/
rm -rf /export/server/apache-hive-3.1.3-bin/lib/mysql-connector-java-5.1.42.jar
再次重启报了另外错误:
Underlying cause: java.sql.SQLException : The server time zone value '�й���ʱ��' is unrecognized or represents more than one time zone. You must configure either the server or JDBC driver (via the serverTimezone configuration property) to use a more specifc time zone value if you want to utilize time zone support.
#解决办法:增加以下配置
终于成功了

启动hive
#先创建日志文件夹
mkdir logs
#启动元数据服务
前台启动
bin/hive --service metastore
后台启动
nohup bin/hive --service metastore >>logs/metastore.log 2>&1 &
查看日志
cd logs
tail -f metastore.log
#启动hive
bin/hive
尝试hive操作
#建表
create table test(id INT,name STRING ,gender STRING);
#插入数据
INSERT INTO test VALUES(1,'王力红','男'),(2,'jeff','男'),(3,'林志灵','女');
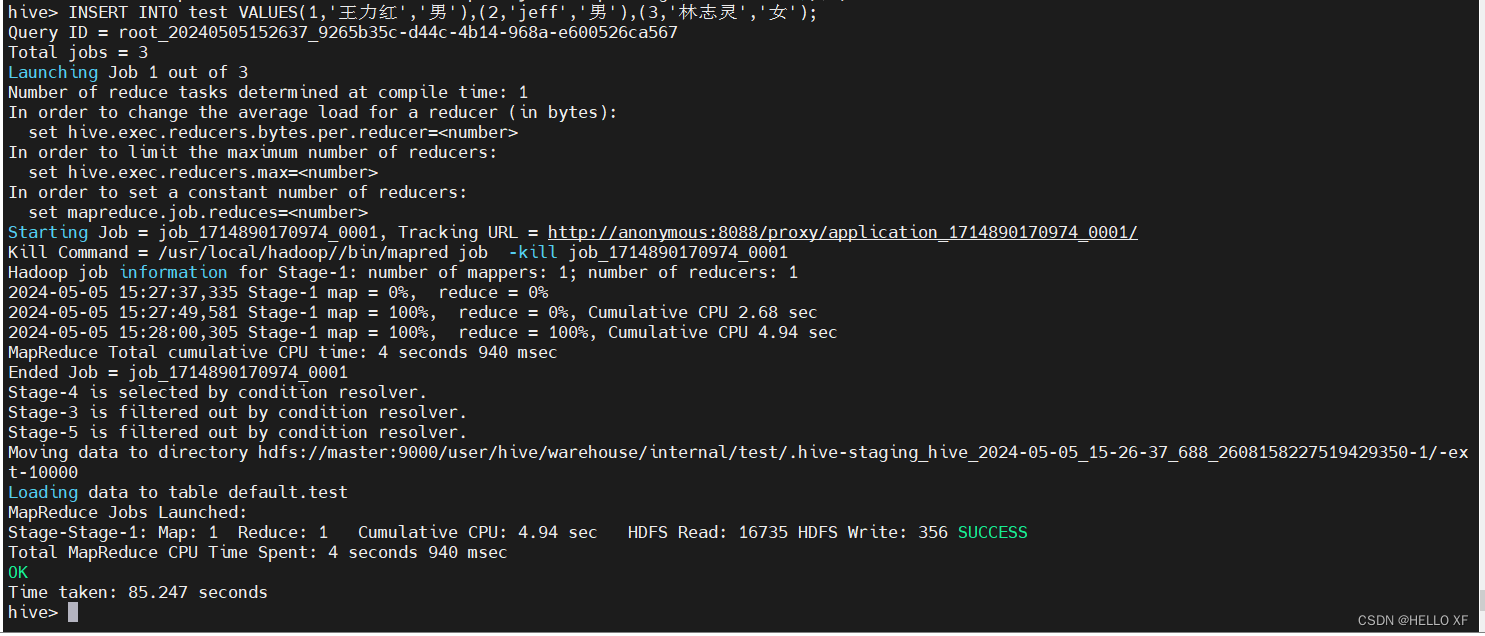
select * from test;

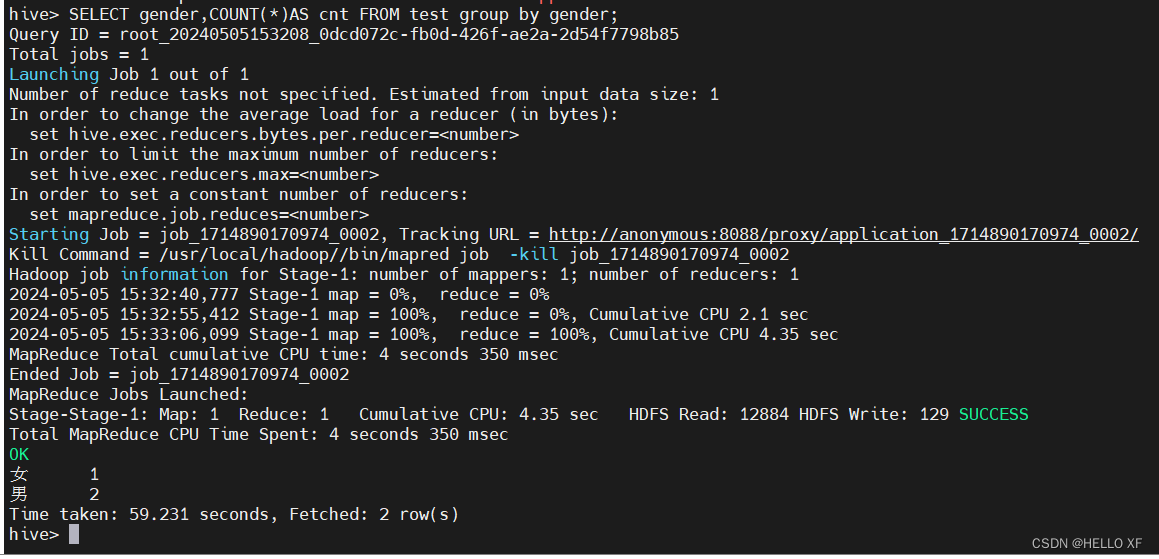
SELECT gender,COUNT(*)AS cnt FROM test group by gender;

#退出hive
exit;
#查看hadoop的存储
hadoop fs -ls /user/hive/warehouse

#查看之前存的数据
hadoop fs -cat /user/hive/warehouse/internal/test/*

hiveserver2实战
#先启动metastore服务然后启动hiveserver2服务
nohup bin/hive --service metastore >> logs/metastore.log 2>&1 &
nohup bin/hive --service hiveserver2 >> logs/hiveserver2.log 2>&1 &
备注: JPS 显示RUNjar服务就是matestore
#查看hiveserver2服务
ps -ef|grep 42669
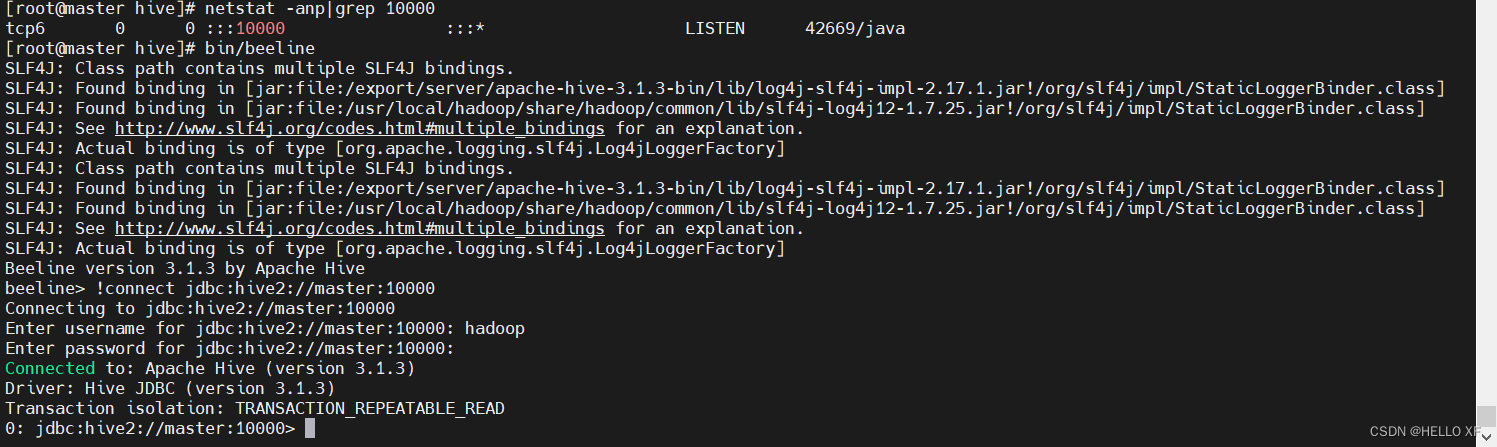
#查看端口占用
netstat -anp|grep 10000

#启动beeline
bin/beeline
#链接到hiveserver2
!connect jdbc:hive2://master:10000
输入用户名 hadoop
密码跳过
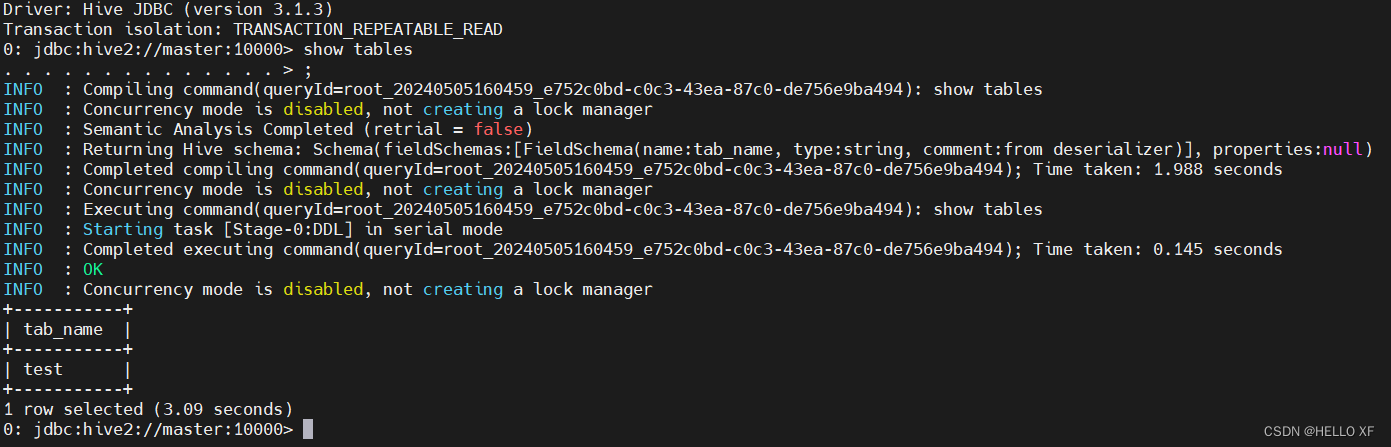
#查看表
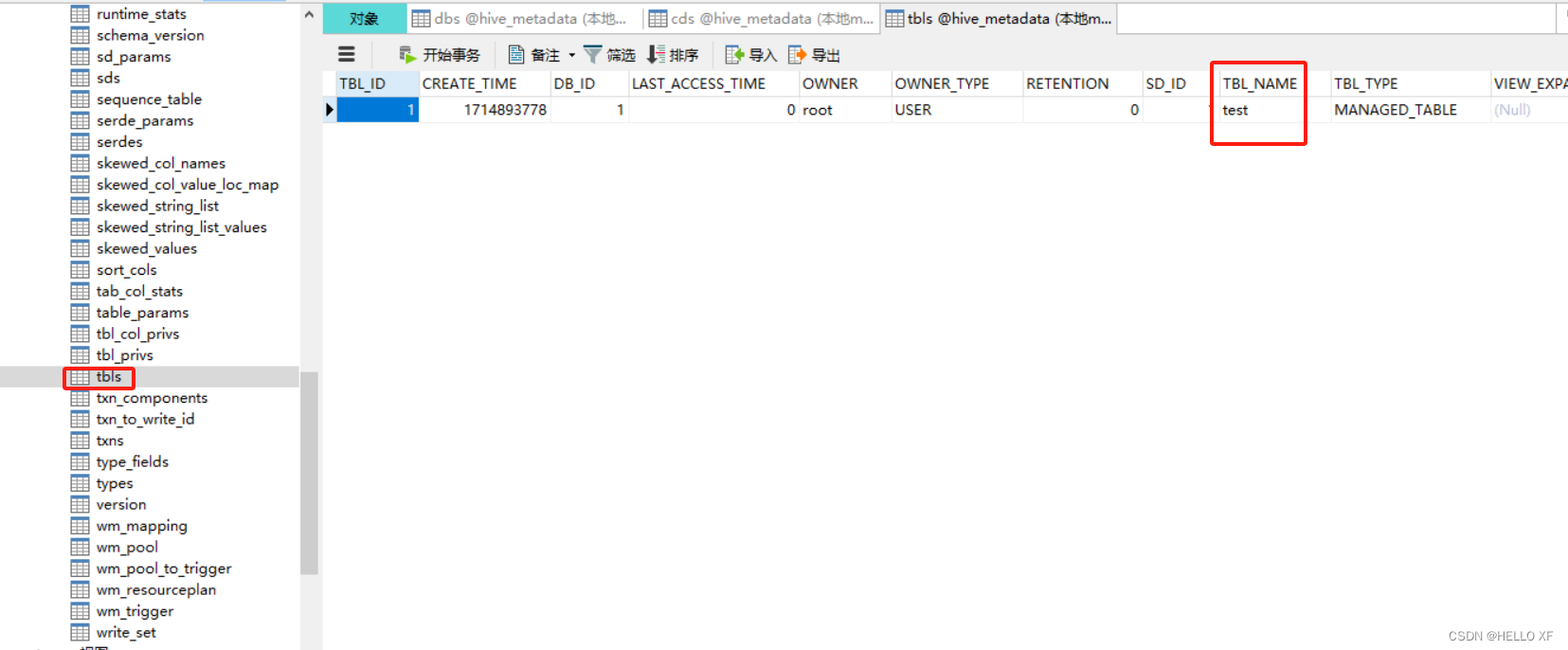
HIVE的表
Hive 是一种基于 Hadoop 的数据仓库工具,用于存储、查询和分析大规模数据。Hive 支持多种表类型,每种表类型都有其特定的用途和特性。
-
**内部表(Managed Table)**:这是 Hive 默认创建的表类型。当删除内部表时,HDFS 上的数据和元数据都会被删除。内部表非常适合用于存储临时数据或不需要长期保留的数据。
-
**外部表(External Table)**:外部表与内部表不同,删除外部表时,仅删除元数据,而 HDFS 上的源数据不会被删除。这使得外部表非常适合用于存储原始数据或需要与其他系统共享的数据。例如,某个公司的原始日志数据存放在一个目录中,多个部门对这些原始数据进行分析,那么创建外部表就是比较好的选择。
-
**临时表(Temporary Table)**:临时表只在当前会话中存在,当会话结束后,临时表会自动删除。临时表不支持分区,通常用于存储临时数据或中间结果。
-
**分区表(Partitioned Table)**:分区表将一批数据按照一定的字段或关键字分为多个目录进行存储。分区可以提高查询效率,避免全表扫描。分区字段在源文件中并不存在,需要在添加数据时手动指定。每个分区对应一个目录,目录名由分区字段的值决定。
-
**分桶表(Bucketed Table)**:分桶表将一批数据按照指定好的字段和桶的数量,对指定字段的数据取模运算,分成不同的桶进行存储。分桶可以方便随机取样以及 join 等操作。桶是比表或分区更为细粒度的数据范围划分。桶通常用于数据的采样和连接操作。
Hive的复杂数据类型
Hive的复杂数据类型允许用户存储更丰富的数据结构和处理更复杂的数据场景。以下是Hive中支持的几种主要复杂数据类型:
-
**ARRAY(数组)**: 数组是一种可以包含多个相同类型元素的数据结构。例如,你可以创建一个包含多个字符串的数组或包含多个整数的数组。在Hive中,你可以使用ARRAY类型来定义表的某一列,这样该列就可以存储一个数组。
-
**MAP(映射)**: MAP是一种可以存储键值对数据的数据结构。每个键都是唯一的,并关联一个值。在Hive中,你可以使用MAP类型来定义表的某一列,这样该列就可以存储一个键值对集合。
-
**STRUCT(结构体)**: STRUCT是一种可以包含多个不同类型字段的数据结构。每个字段都有一个名称和一个类型。你可以将STRUCT看作是一个记录或对象,其中包含多个不同属性的集合。在Hive中,你可以使用STRUCT类型来定义表的某一列,这样该列就可以存储一个结构体。
这些复杂数据类型为用户提供了更大的灵活性,使他们能够在Hive中存储和查询更复杂的数据结构。例如,你可以使用ARRAY类型来存储一个用户的兴趣列表,使用MAP类型来存储一个用户的个人信息(如姓名、年龄、地址等),或者使用STRUCT类型来存储一个订单的详细信息(如订单号、商品列表、总价等)。
需要注意的是,虽然Hive支持这些复杂数据类型,但在实际使用中,为了确保查询性能和管理的简单性,建议谨慎使用复杂数据类型,并在必要时考虑将其规范化到更简单的数据结构中。
ETL介绍
ETL,即数据抽取(Extract)、转换(Transform)和加载(Load)的过程,是数据仓库领域中的一个重要概念。简单来说,ETL过程就是从各种数据源中抽取数据,将这些数据按照一定的规则进行转换,并最终将这些数据加载到目标数据仓库或其他数据存储系统中。
在ETL过程中,数据抽取阶段主要涉及到从各种数据源(如关系型数据库、非关系型数据库、文件、API等)中读取数据,并将其提取出来。这个阶段需要解决数据连接、数据格式转换等问题。
数据转换阶段则是对提取出来的数据进行清洗、加工、转换等操作,以确保数据的准确性、一致性和完整性。例如,去除重复数据、处理缺失值、数据格式转换、数据聚合等。
最后,数据加载阶段则是将转换后的数据加载到目标数据仓库或其他数据存储系统中。加载过程可能需要考虑数据的存储结构、索引设计、分区策略等问题,以提高数据查询和分析的效率。
总的来说,ETL过程是数据仓库建设中的一个重要环节,它能够实现数据的整合、清洗和转换,为数据分析和决策提供支持。同时,ETL过程也需要考虑数据的准确性、一致性和效率等方面的问题,以确保数据的质量和价值。

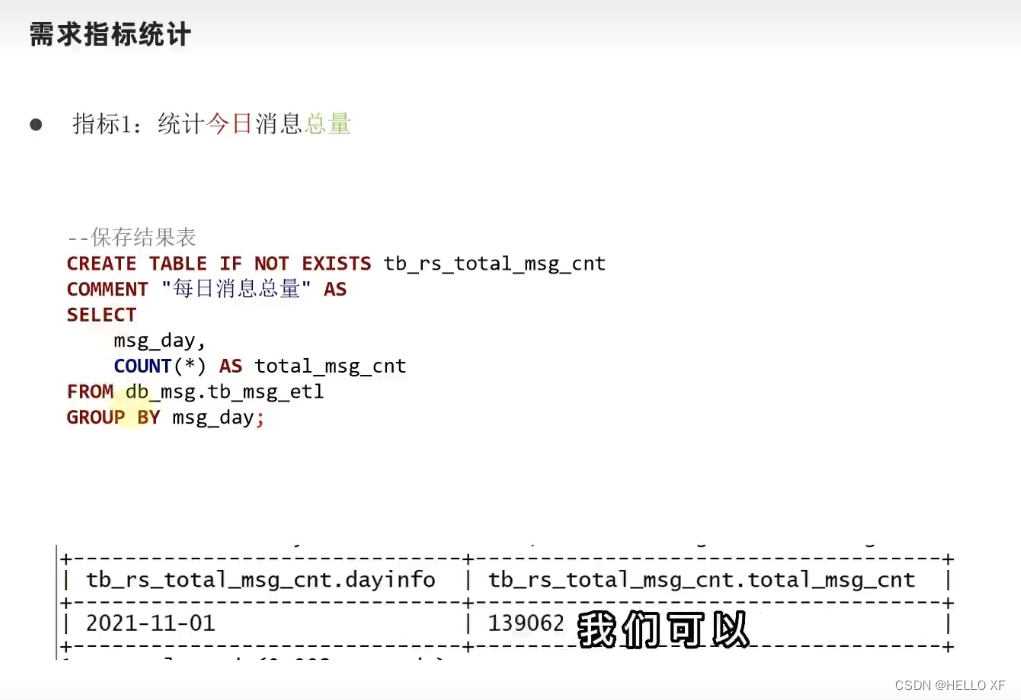
指标
指标(Metrics):在数据仓库中,指标是对业务活动的度量和监控,它们通常是数量、比率、百分比、平均值等各种形式。这些指标反映了业务的运行状态和企业的经营状况,对于企业的管理决策有着重要的影响。指标的设计需要考虑到业务需求和数据的特点,以确保能够准确、全面地反映业务的实际情况。
#BI
BI,即商业智能(Business Intelligence)的缩写,是一种通过收集、整合、分析和可视化企业内外部数据,以提供对业务运营和决策支持的技术、工具和方法。它利用现代数据仓库技术、线上分析处理技术、数据挖掘和数据展现技术来分析和实现商业价值。
商业智能技术旨在帮助企业从海量数据中提取有价值的信息,发现数据中的模式、趋势和关联,以支持管理层制定战略决策、优化业务运营、改进绩效,并获取竞争优势。通过BI,企业可以将分散的数据整合起来,进行数据分析、探索和可视化,以获得深入的洞察力。它可以帮助用户快速获取所需的信息,了解业务运营的情况,预测未来的趋势,发现业务中的机会和挑战,并进行实时监控和反馈。
商业智能一般由数据仓库、联机分析处理、数据挖掘、数据备份和恢复等部分组成。其中,数据仓库是商业智能的核心,它存储和管理企业的数据,并提供给其他组件进行分析和查询。联机分析处理(OLAP)工具可以对数据进行多维度的分析,数据挖掘工具则可以发现数据中的隐藏模式和关系。
商业智能的应用范围非常广泛,可以应用于各种行业,如石油化工、房地产、制造等。在石油化工行业中,BI数据分析应用多分布于供应链优化、库存管理、资金统一管理和生产监管优化等模块。在房地产行业中,BI可以打破数据孤岛,支持多数据源跨院取数,实现数据采集和整理的流程规范化,形成准确的、统一的数据平台,从而支持企业实现信息化整体管控。在制造行业中,BI技术可以帮助制造企业进行更有效率与收益的管理,把企业的经营信息及其分析技术向基层普及,以方便员工做出最佳决策。
总的来说,商业智能是一种利用数据和技术来支持企业决策制定和业务优化的一种方法和工具集合。它可以帮助企业更好地理解业务情况、发现机会和挑战,并基于数据驱动地做出决策,以实现业务增长和持续竞争优势。
FINEBI帆软BI可以基于指标等数据做报表、大屏等可视化展现
磨刀不误砍柴工
Linux常用命令
sudu
在Linux系统中允许普通用户以超级用户(root)的身份执行命令。
使用“sudo”命令可以提高系统安全性,因为它减少了root用户的登录和管理时间,同时确保只有授权用户可以执行特定的命令。
#建文件夹
sudo mkdir /usr/lib/jvm
#关防火墙
systemctl stop firewalld.service
systemctl stop firewalld
#查看主机名
hostname
#临时修改主机名
[root@localhost ~]# hostname local //临时修改主机名,关机后失效
[root@localhost ~]# hostname
local
#永久修改主机名
[root@localhost ~]# vi /etc/hostname //vim进入主机配置文件
localhost //删除旧主机名,输入新主机名,
:wq //esc后,:wq保存退出
[root@localhost ~]# reboot
#删除
rm
-
-f或--force。强制删除,忽略不存在的文件,不提示确认。
-
-i。在删除前需要确认。
-
-r或-R或--recursive。递归删除目录及其内容。
-
-v或--verbose。详细显示进行的步骤。
-
-d。删除空目录。
-
--help。显示帮助信息并退出。
-
--version 显示版本信息并退出。
#查看启动服务
ps -ef|grep 42669
查看端口占用
netstat -anp|grep 10000
hadoop命令
查看namenodes配置
hdfs getconf -namenodes